Search K
Appearance
每种编程语言都具有内建的数据类型,但它们的数据类型常有不同之处,使用方式也很不一样,比如 C 语言在定义变量之前,就需要确定变量的类型,你可以看下面这段 C 代码:
int main()
{
int a = 1;
char* b = "极客时间";
bool c = true;
return 0;
}上述代码声明变量的特点是:在声明变量之前需要先定义变量类型。这种在使用之前就需要确认其变量数据类型的称为静态语言。相反地,把在运行过程中需要检查数据类型的语言称为动态语言。比如 JavaScript 就是动态语言,因为在声明变量之前并不需要确认其数据类型。
虽然 C 语言是静态,但是在 C 语言中,可以把其他类型数据赋予给一个声明好的变量。如把 int 型的变量 a 赋值给了 bool 型的变量 c,这段代码也是可以编译执行的,因为在赋值过程中,C 编译器会把 int 型的变量悄悄转换为 bool 型的变量,通常把这种偷偷转换的操作称为隐式类型转换。而支持隐式类型转换的语言称为弱类型语言,不支持隐式类型转换的语言称为强类型语言。在这点上,C 和 JavaScript 都是弱类型语言。
对于各种语言的类型,你可以参考下图:
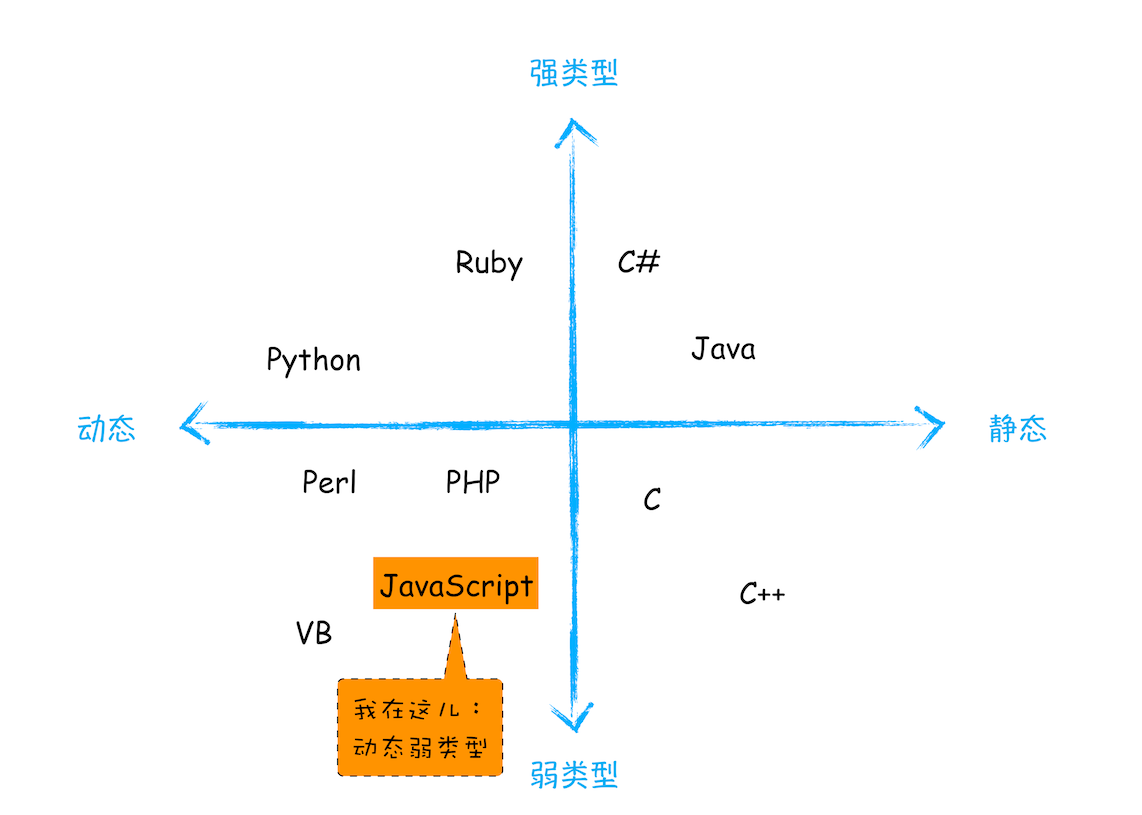
JavaScript 是一种弱类型的、动态的语言。
其实 JavaScript 中的数据类型一种有 8 种,它们分别是:

前面的 7 种数据类型称为原始类型,把最后一个对象类型称为引用类型,之所以把它们区分为两种不同的类型,是因为它们在内存中存放的位置不一样
栈空间就是之前提及的调用栈,是用来存储执行上下文的。为了搞清楚栈空间是如何存储数据的,我们还是先看下面这段代码:
function foo() {
var a = "极客时间";
var b = a;
var c = { name: "极客时间" };
var d = c;
}
foo();当执行一段代码时,需要先编译,并创建执行上下文,然后再按照顺序执行代码。其调用栈的状态,参考下面这张调用栈状态图:
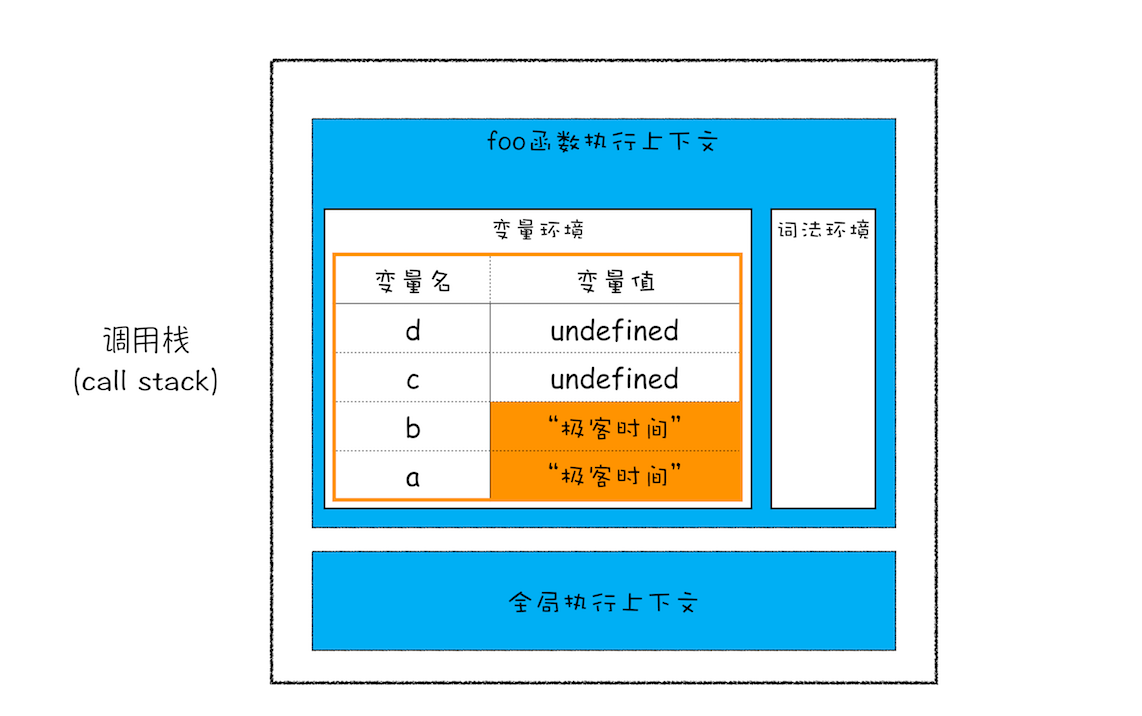
从图中可以看出来,当执行到第 3 行时,变量 a 和变量 b 的值都被保存在执行上下文中,而执行上下文又被压入到栈中,也可以认为变量 a 和变量 b 的值都是存放在栈中的。
接下来继续执行第 4 行代码,由于 JavaScript 引擎判断右边的值是一个引用类型,这时候处理的情况就不一样了,JavaScript 引擎并不是直接将该对象存放到变量环境中,而是将它分配到堆空间里面,分配后该对象会有一个在“堆”中的地址,然后再将该数据的地址写进 c 的变量值,最终分配好内存的示意图如下所示:
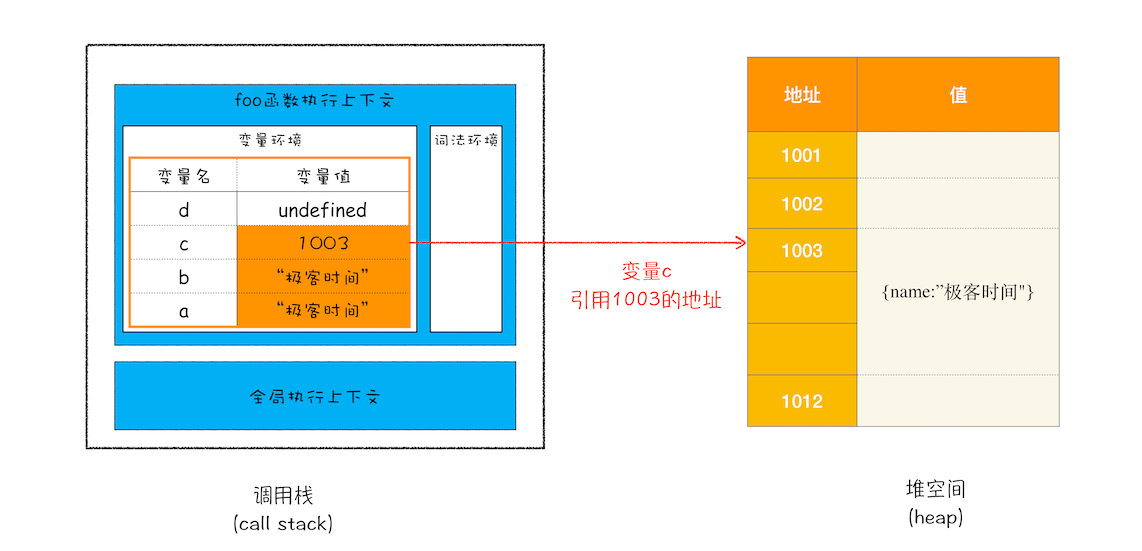
从上图你可以清晰地观察到,对象类型是存放在堆空间的,在栈空间中只是保留了对象的引用地址,当 JavaScript 需要访问该数据的时候,是通过栈中的引用地址来访问的,相当于多了一道转手流程。
为什么原始类型的数据值都是直接保存在“栈”中的,引用类型的值是存放在“堆”中的呢?因为 JavaScript 引擎需要用栈来维护程序执行期间上下文的状态,如果栈空间大了话,所有的数据都存放在栈空间里面,那么会影响到上下文切换的效率,进而又影响到整个程序的执行效率。
所以通常情况下,栈空间都不会设置太大,主要用来存放一些原始类型的小数据。而引用类型的数据占用的空间都比较大,所以这一类数据会被存放到堆中,堆空间很大,能存放很多大的数据,不过缺点是分配内存和回收内存都会占用一定的时间。
解释了程序在执行过程中为什么需要堆和栈两种数据结构后,回到示例代码那里,看看它最后一步将变量 c 赋值给变量 d 是怎么执行的?在 JavaScript 中,赋值操作和其他语言有很大的不同,原始类型的赋值会完整复制变量值,而引用类型的赋值是复制引用地址。
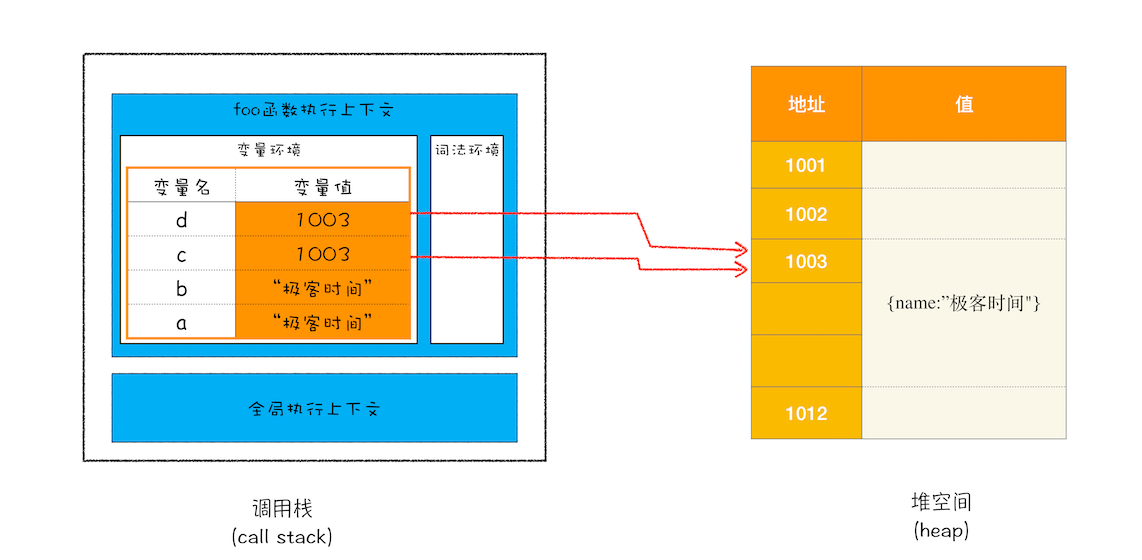
function foo() {
var myName = "极客时间";
let test1 = 1;
const test2 = 2;
var innerBar = {
setName: function (newName) {
myName = newName;
},
getName: function () {
console.log(test1);
return myName;
}
};
return innerBar;
}
var bar = foo();
bar.setName("极客邦");
bar.getName();
console.log(bar.getName());当执行这段代码的时候:由于变量 myName、test1、test2 都是原始类型数据,所以在执行 foo 函数的时候,它们会被压入到调用栈中;当 foo 函数执行结束之后,调用栈中 foo 函数的执行上下文会被销毁,其内部变量 myName、test1、test2 也应该一同被销毁。但当 foo 函数的执行上下文销毁时,由于 foo 函数产生了闭包,所以变量 myName 和 test1 并没有被销毁,而是保存在内存中。
我们就得站在内存模型的角度来分析这段代码的执行流程。
总的来说,产生闭包的核心有两步:第一步是需要预扫描内部函数;第二步是把内部函数引用的外部变量保存到堆中。
前端工具和框架的自身更新速度非常快,而且还不断有新的出现。要想追赶上前端工具和框架的更新速度,就需要抓住那些本质的知识,然后才能更加轻松地理解这些上层应用。比如我们接下来要介绍的 V8 执行机制,从底层了解 JavaScript,深入理解语言转换器 Babel、语法检查工具 ESLint、前端框架 Vue 和 React 的一些底层实现机制。因此,了解 V8 的编译流程能对语言以及相关工具有更加充分的认识。
要深入理解 V8 的工作原理,就需要搞清楚一些概念和原理,比如接下来要详细讲解的编译器(Compiler)、解释器(Interpreter)、抽象语法树(AST)、字节码(Bytecode)、即时编译器(JIT)等概念。
之所以存在编译器和解释器,是因为机器不能直接理解我们所写的代码,所以在执行程序之前,需要将我们所写的代码“翻译”成机器能读懂的机器语言。按语言的执行流程,可以把语言划分为编译型语言和解释型语言。
编译型语言在程序执行之前,需要经过编译器的编译过程,并且编译之后会直接保留机器能读懂的二进制文件,这样每次运行程序时,都可以直接运行该二进制文件,而不需要再次重新编译了。比如 C/C++、GO 等都是编译型语言。
解释型语言编写的程序,在每次运行时都需要通过解释器对程序进行动态解释和执行。比如 Python、JavaScript 等都属于解释型语言。
那编译器和解释器是如何“翻译”代码的呢?具体流程你可以参考下图:
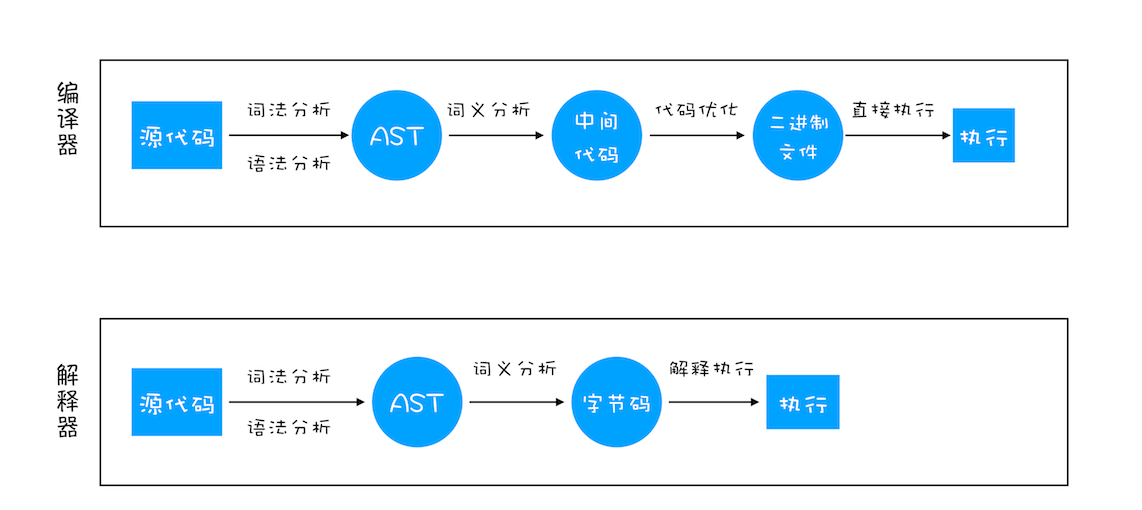
从图中你可以看出这二者的执行流程,大致可阐述为如下:
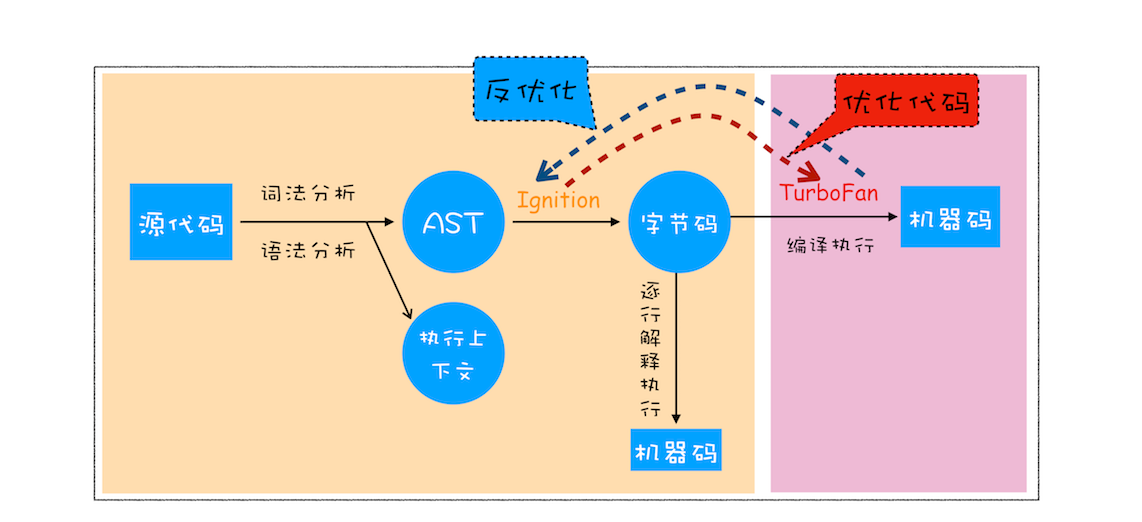
从图中可以清楚地看到,V8 在执行过程中既有解释器 Ignition,又有编译器 TurboFan,那么它们是如何配合去执行一段 JavaScript 代码的呢? 下面按照上图来一一分解其执行流程。
1.生成抽象语法树(AST)和执行上下文
将源代码转换为抽象语法树,并生成执行上下文,而执行上下文在前面的文章中已经介绍过很多了,主要是代码在执行过程中的环境信息。
下面我们就得重点讲解下抽象语法树(下面表述中就直接用它的简称 AST 了),看看什么是 AST 以及 AST 的生成过程是怎样的。
高级语言是开发者可以理解的语言,但是让编译器或者解释器来理解就非常困难了。对于编译器或者解释器来说,它们可以理解的就是 AST 了。所以无论你使用的是解释型语言还是编译型语言,在编译过程中,它们都会生成一个 AST。这和渲染引擎将 HTML 格式文件转换为计算机可以理解的 DOM 树的情况类似。
AST 的结构和代码的结构非常相似,其实也可以把 AST 看成代码的结构化的表示,编译器或者解释器后续的工作都需要依赖于 AST,而不是源代码。AST 是非常重要的一种数据结构,在很多项目中有着广泛的应用。其中最著名的一个项目是 Babel。
Babel 是一个被广泛使用的代码转码器,可以将 ES6 代码转为 ES5 代码,这意味着你可以现在就用 ES6 编写程序,而不用担心现有环境是否支持 ES6。Babel 的工作原理就是先将 ES6 源码转换为 AST,然后再将 ES6 语法的 AST 转换为 ES5 语法的 AST,最后利用 ES5 的 AST 生成 JavaScript 源代码。除了 Babel 外,还有 ESLint 也使用 AST。
ESLint 是一个用来检查 JavaScript 编写规范的插件,其检测流程也是需要将源码转换为 AST,然后再利用 AST 来检查代码规范化的问题。现在你知道了什么是 AST 以及它的一些应用,那接下来我们再来看下 AST 是如何生成的。通常,生成 AST 需要经过两个阶段。
第一阶段是分词(tokenize),又称为词法分析
第二阶段是解析(parse),又称为语法分析,其作用是将上一步生成的 token 数据,根据语法规则转为 AST
2.生成字节码
解释器 Ignition 就登场了,它会根据 AST 生成字节码,并解释执行字节码。
字节码就是介于 AST 和机器码之间的一种代码。但是与特定类型的机器码无关,字节码需要通过解释器将其转换为机器码后才能执行。

3.执行代码
对于优化 JavaScript 执行效率,你应该将优化的中心聚焦在单次脚本的执行时间和脚本的网络下载上,主要关注以下三点内容: